

16 novembre 2021
9 minutes

L’intelligence artificielle de Dynatrace au service de la prédiction d’anomalies
Depuis quelques années déjà le monitoring de systèmes informatiques a fait un grand pas en avant grâce à l'intelligence artificielle (IA). La complexité des systèmes et de leurs paramètres est d'ailleurs telle que seuls les algorithmes puissants issus de l'IA peuvent "comprendre" la relation entre toutes les données pour pouvoir remonter aux causes racines des problèmes. (Root cause dans le jargon de la métrologie)
Une des disciplines de l’IA est appelée le machine learning (ML). Cette discipline décrit des algorithmes qui permettent aux ordinateurs d’apprendre à résoudre des problèmes spécifiques, sans pour autant coder les stratégies de résolution elles-mêmes dans du code.
Très simplifié, on procède souvent par trois étapes :
- Échantillonnage et nettoyage des données,
- Entrainement avec ces échantillons (le learn-set) et un modèle,
- Vérification de la pertinence du modèle avec d’autres échantillons gardés de côté pour vérifier le bon apprentissage (le test-set), et ensuite prédiction avec des données « réelles ».
Il s’agit donc essentiellement de prédire une valeur en fonction d’un modèle et d’un état du système (et potentiellement la comparer avec la réalité pour détecter une anomalie).
Un des outils souvent cités dans ce contexte du machine learning, les réseaux neuronaux, peut donner des résultats spectaculaires notamment lorsque le nombre d’échantillons est très important et qu’il n’y a pas d’autre modèle statistique plus adapté.
Mais tout ne tourne pas systématiquement autour de réseaux neuronaux, les modèles d’apprentissage peuvent être très différents d’un problème à l’autre.
S’il s’agit par exemple de prédire la valeur f(4) de la suite f(1)->4, f(2)->7, f(3)->10, f(4)->? vous l’aurez compris : d’autres modèles statistiques (ici p.ex. la simple régression linéaire aboutissant à une règle de trois) fourniront la formule gagnante f(x)=3x+1 sans fatiguer des réseaux neuronaux.
La connaissance des données et de leur distribution joue donc un grand rôle dans le choix des stratégies. Le but étant de détecter les anomalies, il s’agit donc de détecter ce qui est ‘statistiquement improbable’ : la connaissance du système et son environnement sont donc indispensables.
L’API (interface d’interrogation par programmation) du moteur de Dynatrace par exemple permet de récupérer les mesures. Mais Dynatrace nous laisse également regarder l’avenir en passant l’argument ‘predict=true’.
Cela donne une idée de la puissance du moteur IA :
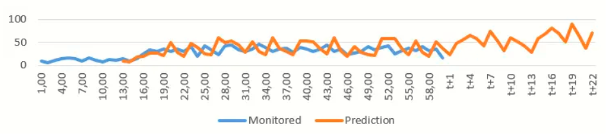
La prédiction des données (par exemple sur le volume des requêtes) pourrait servir à dynamiquement dimensionner des équipements dans des environnements de cloud (provisionnement, décommissionnement de pods dans Kubernetes, par exemple).
Mais actuellement nous exploitons surtout la prédiction immédiate du moteur qui consiste à détecter des anomalies en fonction de l’écart improbable entre la prédiction et la valeur observée à l’instant.
La société Dynatrace a fait le choix de construire dès 2014 une nouvelle solution basée sur un moteur d’intelligence artificielle. Initialement créée dans une start-up de Dynatrace concurrente à la solution AppMon du même éditeur et nommée Ruxit, elle a été rapatriée et rebaptisée Dynatrace en 2016.
À l’époque le constat était qu’il n’y avait plus de sens à observer des tableaux de bords en permanence, vu la complexité des environnements dans le cloud et de l’explosion du nombre de mesures et de la relation entre elles.
Plutôt que de positionner des alertes, autant faire détecter les anomalies par un moteur d’IA.
Le moteur d’IA de Dynatrace (nommé Davis) a été pensé dès le départ pour répondre à des exigences fortes en termes de volumétrie, de précision et de vitesse pour des environnements complexes et dynamiques, voire éphémères, comme ceux trouvés dans le cloud computing.
Les agents (nommés OneAgent) de Dynatrace s’injectent partout où il est possible dans l’écosystème, de manière automatique et en traversant toutes les couches de l’infrastructure et du réseau jusqu’aux microservices et containeurs. C’est ce que l’on appelle un monitoring full-stack.
La capacité de s’infiltrer partout donne à Dynatrace la possibilité de faire le lien entre les différentes mesures, capturées en permanence sur tout le système, de bout en bout, 24h sur 24, sans échantillonnage et déversées dans un dépôt big data pour être analysé par Davis. Cette démarche permet d’avoir une vue d’ensemble de l’écosystème, ce qui permet à Dynatrace de construire automatiquement un arbre de dépendance à tout moment.
Ce lien entre les points de mesures sera déterminant pour remonter à la cause racine lors de la détection d’anomalies.
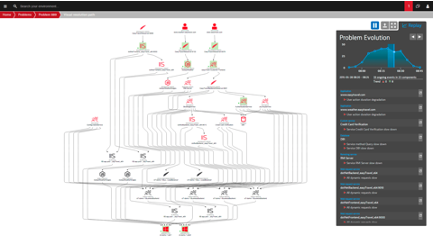
Le moteur IA n’est pas basé sur un apprentissage type réseaux neuronaux, c’est un moteur déterministe, avec une panoplie de modèles statistiques adaptés au domaine de la métrologie.
Typiquement, un des soucis en prédiction d’anomalies est que les données évoluent avec le temps et comportent de la saisonnalité (exemple : moins de trafic le week-end, les nuits) et des dérives lentes (trend en anglais) qui peuvent être dus à l’augmentation du trafic suite à l’ouverture d’un service, des ralentissements dans le temps suite à un vieillissement d’une infrastructure, etc...
| Un signal observé : | 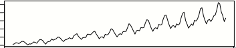 |
| Extraction de sa dérive (trend ) : |  |
| Extraction de sa saisonnalité : | 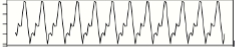 |
| Après soustractions voici le signal à analyser : | 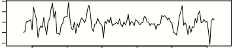 |
Le moteur d’IA de Dynatrace applique par exemple des algorithmes bien connus des statisticiens pour retirer la saisonnalité d’un signal, trouver le couloir entre le minimum et le maximum probable statistiquement etc. On peut citer dans les algorithmes utilisés celui de Holt-Winters, qui applique un lissage exponentiel aux données : le lissage exponentiel donne aux observations passées un poids décroissant exponentiellement avec leur ancienneté, ce qui permet de mieux s’adapter à des évolutions du signal dans le temps.
Les algorithmes dits de ‘smart baselining’ déterminent et apprennent le comportement jugé normal d’un signal en fonction des observations récentes (typiquement une semaine).
Les algorithmes du ‘random surfer’ déterminent le poids de certains signaux par rapport à d’autres. Ce sont des algorithmes mathématiquement proches du ‘page ranking’ qui définit le poids de pages chez Google… et il y a bien d’autres défis dans l’analyse de données : le moteur d’IA de Dynatrace doit par exemple déterminer si deux échantillons suivent la même loi statistique. Il se sert d’un test connu des statisticiens, le test de Kolmogorov-Smirnov, pour y parvenir.
Toutes les mesures et seuils ne sont pas pour autant déterminés par de l’apprentissage et parfois la bonne connaissance du terrain est incorporée dans les algorithmes : le moteur incorpore par exemple des alertes avec des valeurs empiriques établies en métrologie (p.ex. alerter si un disque atteint 3% de libre) – Même si elles peuvent être ajustées, elles partent du bon sens et de l’observation sur le terrain.
Le tout prend tout son sens lorsque l’arbre de causalité construit par le moteur permet de relier tous ces résultats dans un graphe. En parcourant des milliards de nœuds de l'arborescence par milliseconde, il peut remonter rapidement à la cause racine.

En conclusion le moteur d’IA s’appuie sur des algorithmes déterministes et spécifiques au domaine d’expertise pour faire ses prédictions.
Notre expérience chez Tenedis montre que le moteur détermine les bonnes causes racines dans un très grand nombre de cas, au-dessus de 85%, à condition que toute la chaîne applicative soit instrumentée bien entendu
Il reste néanmoins nécessaire de faire une analyse de pertinence humaine pour s’assurer du fondement des alertes.
Un travail préalable est également nécessaire pour réduire le ‘bruit’ des alertes trop nombreuses sans réglage fin. Mais ce couplage du savoir-faire humain et de l’intelligence artificielle est très prometteur.
L’enjeu reste le même : garantir la satisfaction des utilisateurs, gardons-le à l’esprit.
Un retard de +100ms sur le temps de chargement équivaut à une perte de 1% de revenues (source : Amazon)
Les utilisateurs quittent un site dès lors qu’il met plus de 2,5 secondes à s’afficher (source : Forrester Research)
Article rédigé par Pascal Specht, Performance Success Manager.
Vous souhaitez en savoir plus sur notre expertise Dynatrace ?
Vous pouvez télécharger notre fiche expertise :





