

25 septembre 2021
9 minutes
Pour garder le leadership et une bonne réputation dans un monde fortement concurrentiel il faut être en mesure de quantifier et suivre les indicateurs essentiels des applications.
Depuis quelques années déjà le monitoring de systèmes informatiques a fait un grand pas en avant grâce à l’intelligence artificielle (IA). L’observabilité des systèmes est améliorée grâce à des outils de nouvelle génération comme Dynatrace. La démarche globale du monitoring applicatif a évolué en l’inscrivant dans une approche DevOps : les outils d’observabilité assistés par l’IA comme Dynatrace ont conquis les chaînes d’intégration continue (CI), accompagnent les tests de charges, épaulent les ingénieurs (y compris les product owners) et le métier dans le suivi quotidien des applications en production et ils s’inscrivent dans d’autres domaines comme le capacity planning, la prédiction d’incidents, la remédiation automatique.
 Cette ambition de recherche de qualité et d’amélioration continue est souvent favorablement accompagnée d’une démarche DevOps. Fort d’une grande expérience dans ce domaine, Google a partagé et publié des recommandations pour rester à la pointe en termes de disponibilité, latence, performance et capacité, recommandations regroupées sous le terme de SRE (Site Reliability Engineering).
Cette ambition de recherche de qualité et d’amélioration continue est souvent favorablement accompagnée d’une démarche DevOps. Fort d’une grande expérience dans ce domaine, Google a partagé et publié des recommandations pour rester à la pointe en termes de disponibilité, latence, performance et capacité, recommandations regroupées sous le terme de SRE (Site Reliability Engineering).
La démarche SRE donne des recommandations pragmatiques pour améliorer la disponibilité et la performance d’un service informatique : Afin d’augmenter la résilience et la disponibilité, elle préconise trois leviers d’actions :
- La réduction de la fréquence des pannes (par du design judicieux, des tests fonctionnels, tests de charge, etc. et des stratégies de déploiements intelligentes),
- La réduction de l’ampleur des pannes (par de l’isolation géographique, la dégradation contrôlée des services, la redondance,…)
- Et la réduction du temps de réparation des pannes (par le monitoring intelligent, la détection des causes racines, les stratégies de remédiation,…).
C’est sur ce dernier point que l’outil Dynatrace peut apporter les précieuses secondes ou minutes qui réduiront le temps de détection et par conséquent de réparation (les fameux MTTI=mean time to identify et MTTR=mean time to repair). La disponibilité du service étant autant liée à la fréquence de pannes qu’à la durée des pannes, le MTTR est par conséquent une valeur que l’on cherche à réduire.
Savoir mesurer, quantifier et alerter tôt est donc un enjeu important, et la démarche SRE propose des façons de quantifier ces objectifs de manière rationnelle et impartiale à travers les SLI, SLO et SLAs.
Autant le terme de SLA (Service Level Agreement) a déjà largement conquis notre langage métier et signifie l’engagement souvent contractuel d’un niveau de qualité de service proposé par un fournisseur, autant les termes SLI et SLO méritent de s’y attarder pour bien comprendre la suite.
D’après la définition de Google, un SLI (Service Level Indicator) est une mesure qui permet de quantifier le niveau de qualité délivré par un service : les SLIs s’expriment souvent en termes de temps de réponse, de taux d’erreur, de débits, ou de disponibilité. Exemples : le temps de réponse moyen d’un service, ou le nombre de requêtes en erreur par rapport au nombre total de requêtes sur une période. Dans Dynatrace, les SLIs sont exprimés par des metrics (en français : mesure ou indicateur).
 Un SLO (Service Level Objective) est une valeur cible que l’on se fixe pour un service mesuré par un SLI, l’ambition étant de viser une qualité de service suffisamment bonne pour que les SLIs respectent et surpassent ces seuils. Exemples : le temps de réponse d’un service ne doit pas dépasser 500ms ou le taux de requêtes en échec ne doit pas dépasser 2%. Dans Dynatrace, les SLOs sont basés sur des indicateurs associés à des seuils et périodes d’observations.
Un SLO (Service Level Objective) est une valeur cible que l’on se fixe pour un service mesuré par un SLI, l’ambition étant de viser une qualité de service suffisamment bonne pour que les SLIs respectent et surpassent ces seuils. Exemples : le temps de réponse d’un service ne doit pas dépasser 500ms ou le taux de requêtes en échec ne doit pas dépasser 2%. Dans Dynatrace, les SLOs sont basés sur des indicateurs associés à des seuils et périodes d’observations.
Il n’est pas toujours facile de positionner les SLOs mais l’idée générale est de viser des objectifs en termes de temps de réponses et de disponibilité pour garantir un haut niveau de satisfaction des utilisateurs : avec la forte concurrence des offres, une application lente ou instable représente un risque économique. Les clients mécontents se tournent rapidement vers la concurrence. La satisfaction utilisateur est devenu le nerf de la guerre, les SLIs et SLOs servent à la quantifier, la surveiller et travailler sur son amélioration continue.
Dynatrace a incorporé la notion de SLOs depuis décembre 2020 dans son offre de plateforme d’observabilité basée sur l’IA.
 D’abord introduit dans la solution d’orchestration de cycle de vie keptn, Dynatrace y propose de définir des SLIs en formalisant des indicateurs via une description par liste clés/valeurs : on peut y combiner plusieurs indicateurs (en provenance des mesures de Dynatrace, mais également d’autres écosystèmes comme Prometheus ou des outils de tests de charges comme NeoLoad). Toujours dans keptn, on y formalise également les SLOs par une description de l’objectif, avec la possibilité d’y pondérer et combiner des SLIs. En bref, il s’agit d’y définir les critères et conditions auxquels on veut répondre pour atteindre les objectifs, avec la possibilité de s’imposer des seuils de satisfaction (warning, passed).
D’abord introduit dans la solution d’orchestration de cycle de vie keptn, Dynatrace y propose de définir des SLIs en formalisant des indicateurs via une description par liste clés/valeurs : on peut y combiner plusieurs indicateurs (en provenance des mesures de Dynatrace, mais également d’autres écosystèmes comme Prometheus ou des outils de tests de charges comme NeoLoad). Toujours dans keptn, on y formalise également les SLOs par une description de l’objectif, avec la possibilité d’y pondérer et combiner des SLIs. En bref, il s’agit d’y définir les critères et conditions auxquels on veut répondre pour atteindre les objectifs, avec la possibilité de s’imposer des seuils de satisfaction (warning, passed).
L’outil d’orchestration keptn peut ensuite être déclenché par l’extérieur (p.ex. par un trigger d’une chaîne d’intégration continue, un outil de test de charge, ou un outil de déploiement) afin d’évaluer un système par rapport aux objectifs fixés. Dynatrace a choisi le terme évoquant de « quality gates » pour dénommer cette étape : keptn va chercher les mesures dans Dynatrace, NeoLoad, Prometheus etc via des apis, les compare avec les objectifs, et donne son verdict (Les SLOs sont-ils atteints par rapport aux SLIs mesurés? ). Le jugement de keptn lui permet alors de revenir vers son environnement de CI, de build, de test de charge etc. avec ses décisions qui permettront l’orchestration de la suite : release acceptée, déploiement ou rollback, mise en place d’une remédiation ou autres actions. keptn évolue aujourd’hui sous forme d’un projet open source de la CNCF (cloud native computing foundation)
 Le support des SLOs est également incorporé dans la solution AIOps principale Dynatrace (nouveau menu Cloud Automation -> Service level objectives, anciennement directement sous le menu SLO).
Le support des SLOs est également incorporé dans la solution AIOps principale Dynatrace (nouveau menu Cloud Automation -> Service level objectives, anciennement directement sous le menu SLO).
La notion de SLOs dans Dynatrace reprend d’ailleurs un autre indicateur cher au SRE de Google, le budget d’erreurs (error budget). Il correspond à l’écart entre les SLIs mesurés sur une période de référence et l’objectif SLO associé et représente un budget que l’équipe SRE doit consacrer à la remédiation durable du souci si l’objectif n’est pas atteint. En revanche si l’objectif a été atteint, l’équipe bénéficie de ce budget pour faire évoluer son produit : en d’autres termes, ce budget favorise une balance entre disponibilité du site et innovation (qui par définition met en péril la disponibilité). Tant que l’équipe n’a pas eu à allouer ce budget à la correction, elle peut le consacrer à l’innovation : c’est donc un moyen d’arbitrer les tensions antinomiques entre stabilité et innovation.
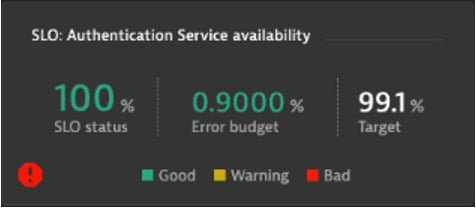 Dynatrace propose une dashlet dédiée pour accueillir des SLOs (ci-contre). Elle reprend les chiffres essentiels de l’objectif : le taux atteint sur la période d’observation, le but fixé, et l’écart. Un code couleur permet de rapidement distinguer les objectifs atteints, en danger, et ratés. Notez dans l’exemple que le moteur d’IA Davis a ajouté une alerte rouge pour informer l’équipe SRE qu’un incident en cours sur la topologie de service couverte par ce SLO : alors même que le SLO est à 100% de ses objectifs, l’IA annonce proactivement que le SLO est potentiellement en danger.
Dynatrace propose une dashlet dédiée pour accueillir des SLOs (ci-contre). Elle reprend les chiffres essentiels de l’objectif : le taux atteint sur la période d’observation, le but fixé, et l’écart. Un code couleur permet de rapidement distinguer les objectifs atteints, en danger, et ratés. Notez dans l’exemple que le moteur d’IA Davis a ajouté une alerte rouge pour informer l’équipe SRE qu’un incident en cours sur la topologie de service couverte par ce SLO : alors même que le SLO est à 100% de ses objectifs, l’IA annonce proactivement que le SLO est potentiellement en danger.
Afin de définir un nouvel objectif SLO dans Dynatrace, rendez-vous dans le menu correspondant (Cloud automation -> Service level objectives). Dynatrace propose alors d’assister l’utilisateur dans la définition de ses objectifs en proposant un guidage selon s’ils sont coté service ou coté client :
 Les SLOs de type service-level concernent des mesures prises sur le ‘back-office’, c’est-à-dire coté services au sens Dynatrace : on peut utiliser toutes les mesures faisant office de SLI y compris les keyRequests, les custom metrics, voire les indicateurs d’autres provenances ajoutées par ingestion. Les SLOs sont déclarés soit en utilisant des mesures simples qui représentent déjà des taux (p.ex. builtin.host.disk.usedPct), soit en déclarant soi-même un taux en divisant deux mesures de même agrégation (count), par exemple :
Les SLOs de type service-level concernent des mesures prises sur le ‘back-office’, c’est-à-dire coté services au sens Dynatrace : on peut utiliser toutes les mesures faisant office de SLI y compris les keyRequests, les custom metrics, voire les indicateurs d’autres provenances ajoutées par ingestion. Les SLOs sont déclarés soit en utilisant des mesures simples qui représentent déjà des taux (p.ex. builtin.host.disk.usedPct), soit en déclarant soi-même un taux en divisant deux mesures de même agrégation (count), par exemple :
 Les SLOs de type client-side concernent des mesures prises sur l’interface (web ou mobile) ou des mesures synthétiques (via robots). Voici un tel exemple avec des indicateurs RUM (real user monitoring ):
Les SLOs de type client-side concernent des mesures prises sur l’interface (web ou mobile) ou des mesures synthétiques (via robots). Voici un tel exemple avec des indicateurs RUM (real user monitoring ):
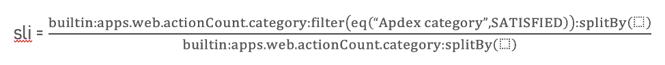 Le ratio dans l’exemple ci-dessus définit le nombre d’actions avec un ressenti utilisateur satisfaisant sur le total des actions utilisateurs. Il n’est pas impératif d’exprimer un ratio entre un numérateur et un dénominateur, vous pouvez également choisir un SLI qui exprime déjà un ratio comme par exemple : builtin.apps.web.conversionRate.
Le ratio dans l’exemple ci-dessus définit le nombre d’actions avec un ressenti utilisateur satisfaisant sur le total des actions utilisateurs. Il n’est pas impératif d’exprimer un ratio entre un numérateur et un dénominateur, vous pouvez également choisir un SLI qui exprime déjà un ratio comme par exemple : builtin.apps.web.conversionRate.
La définition d’un SLO doit ensuite incorporer la notion de seuils (warning, error) et de période d’observation (-1w pour une semaine, par exemple).
Afin de simplifier l’expression des SLIs entre autres, Dynatrace a récemment ajouté les metric expressions au produit. Il permet de combiner des mesures pour en faire des expressions plus complexes : on peut alors faire des calculs arithmétiques comme additionner deux mesures, réduire l’étendue via des filtres ou encore ventiler selon des critères (splitting). Les expressions utilisent des transformers comme filter(), splitBy() etc. Pour les calculs arithmétiques, sachez que les sous-expressions doivent être mises entre parenthèses, y compris des constantes numériques. Exemple : (100) – (builtin.apps.other.crashFreeUsersRate.os). Le plus simple est d’utiliser le nouveau Data Explorer (menu Observe and explore -> Explore data) qui permet d’affiner les expressions avec une assistance de type auto-complétion :
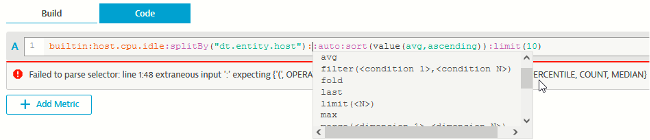 Petite astuce : il est possible d’ajouter un transformer de type :count derrière des mesures si l’agrégation par défaut n’est pas count (voir également les exemples d’usages dans la documentation de l’api https://github.com/Dynatrace/dynatrace-api/blob/master/metric-example/query-by-example.md – Pour voir l’agrégation par défaut d’une mesure, on peut consulter le menu Observe and explore -> Metrics )
Petite astuce : il est possible d’ajouter un transformer de type :count derrière des mesures si l’agrégation par défaut n’est pas count (voir également les exemples d’usages dans la documentation de l’api https://github.com/Dynatrace/dynatrace-api/blob/master/metric-example/query-by-example.md – Pour voir l’agrégation par défaut d’une mesure, on peut consulter le menu Observe and explore -> Metrics )
 L’enjeu reste le même : garantir la satisfaction des utilisateurs, gardons-le à l’esprit.
L’enjeu reste le même : garantir la satisfaction des utilisateurs, gardons-le à l’esprit.
Un retard de +100ms sur le temps de chargement équivaut à une perte de 1% de revenues (source : Amazon)
Les utilisateurs quittent un site dès lors qu’il met plus de 2,5 secondes à s’afficher (source : Forrester Research)
Cet article fait partie des catégories
Techno & solutions
